In supervised learning, there are very good “shallow” models like XGBoost and SVMs. These models can learn powerful classifiers without an artificial neuron in sight. So why, then, is modern reinforcement learning totally dominated by neural networks? My answer: no good reason. And now I want to show everyone that shallow architectures can do RL too.
Right now, using absolutely no feature engineering, I can train an ensemble of decision trees to play various video games from the raw pixels. The performance isn’t comparable to deep RL algorithms yet, and it may never be for vision-based tasks (for good reason!), but it’s fairly impressive nonetheless.
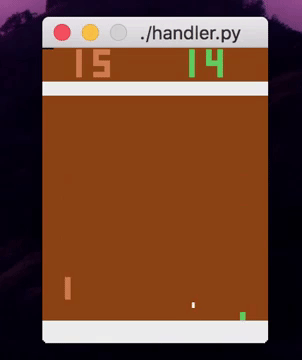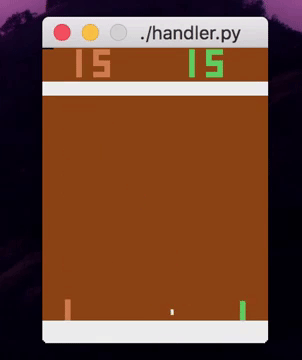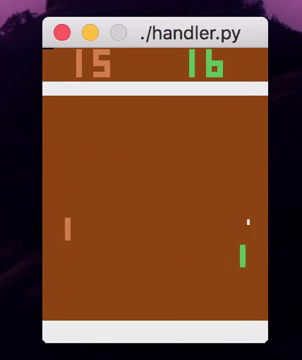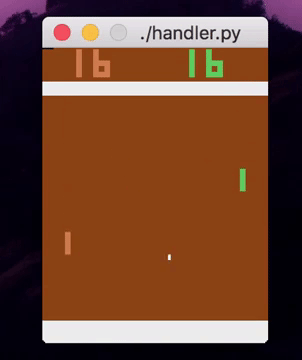
So how exactly do I train shallow models on RL tasks? You might have a few ideas, and so did I. Today, I’ll just be telling you about the one that actually worked.
The algorithm itself is so simple that I’m almost kind of embarrassed by my previous (failed) attempts at tree-based RL. Essentially, I use gradient boosting with gradients from a policy gradient estimator. I call the resulting algorithm policy gradient boosting. In practice, I use a slightly more complex algorithm (a tree-based variant of PPO), but there is probably plenty of room for simplification.
With policy gradient boosting, we build up an ensemble of trees in an additive fashion. For every batch of experience, we add a few more trees to our model, making minor adjustments in the direction of the policy gradient. After hundreds or even thousands of trees, we can end up with a pretty good policy.
Now that I’ve found an algorithm that works pretty well, I want to figure out better hyper-parameters for it. I doubt that tree-based PPO is the best (or even a good) technique, and I doubt that my regularization heuristic is very good either. Yet, even with these somewhat random choices, my models perform well on very difficult tasks! This has convinced me that shallow architectures could really disrupt the modern RL landscape, given the proper care and attention.
All the code for this project is in my treeagent repository, and there are some video demonstrations up on this YouTube playlist. If you’re interested, feel free to contribute to treeagent on Github or send me a PM on Twitter.